Description
Corpus Architecture
Getting the program
PolUkr Corpus Manager is a tool for creating, editing and querying parallel corpora. It was creates within the Polish-Ukrainian Parallel Corpus project (coordinated by dr Natalia Kotsyba).
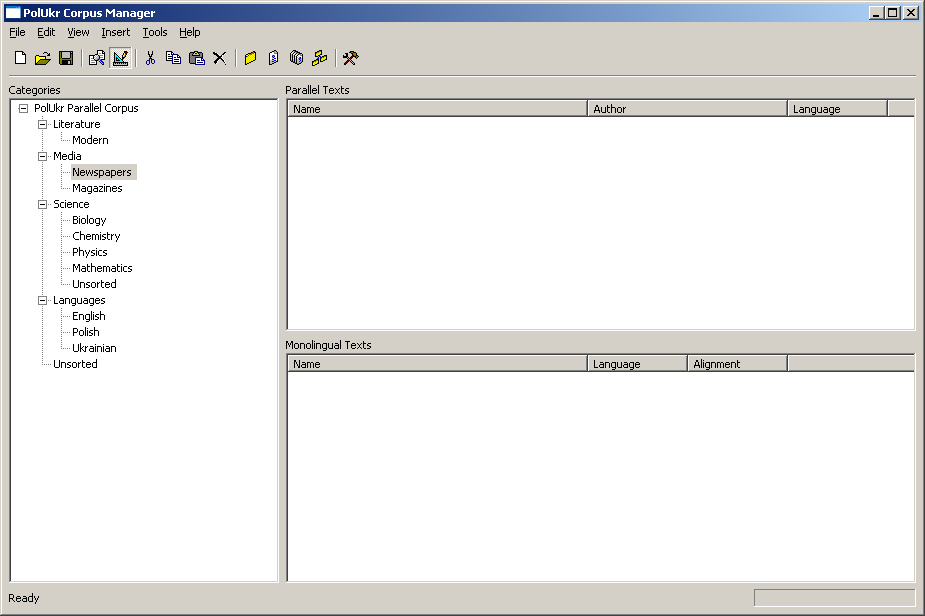
PolUkr corpus basically consist of texts, categories, text alignments and search indexes. Texts are in turn subdivided into monolingual (i.e. Ukrainian or Polish) and parallel. A parallel text is associated with one or more monolingual texts - the original and the translations. Each text can be associated with meta-information, such as name, description, author, year of publishing, editions, etc.
Parallel texts are organized into categories. A category act a symbolic label for text and serves for grouping texts by some criteria. Criteria may include, for example, quality of original text (e.g. poor, proof-read, electronic), genre (literature or text-book), time of creation, and so on. Categories are organized in a tree; the corpus itself is the root category.
Within a parallel text, monolinngual texts may be aligned on the per-sentence basis. Data for such an alignment may come from external programs (such as Hunalign), or from embedded sentence aligner. Moreover, after loading (or otherwise obtaining) alignment data into memory, the users can modify it with intuitive editor.
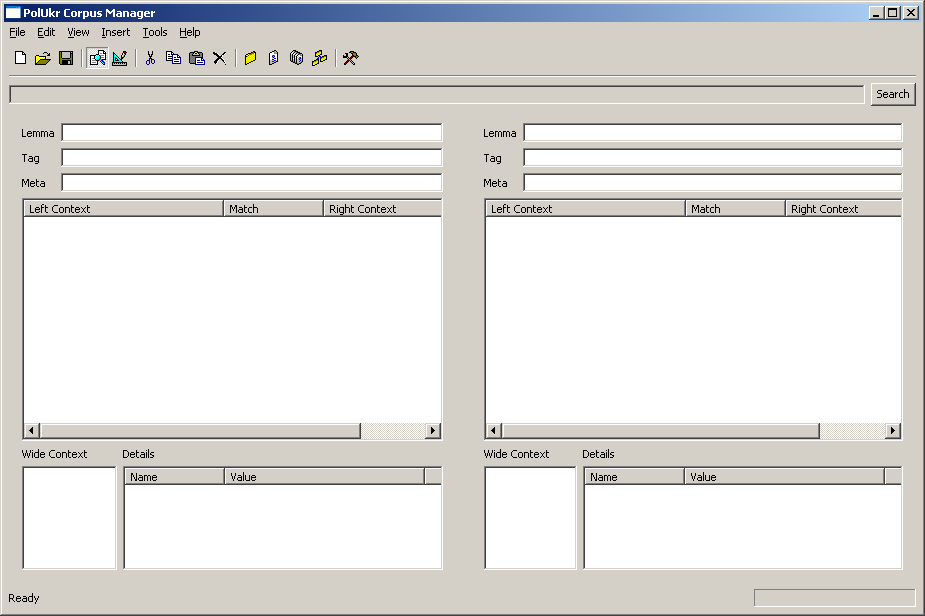
Corpus Query tool provides a means for querying parallel corpus. The user can search information based on word lemmas, grammatical tags or meta-information. For each of the three, regular expressions can be used.
The search results are presented in two synchronized tables - one for Ukrainian and the other one for Polish part. Selecting some piece of information in one part automatically scrolls the other to the corresponding place.
For questions about getting PolUkr please ask dr Natalia Kotsyba (gnatko@gmail.com).
Last updated, 17 October, 2009, by Andriy Mykulyak. See also UGTag and project time-line